
Annotation Platform
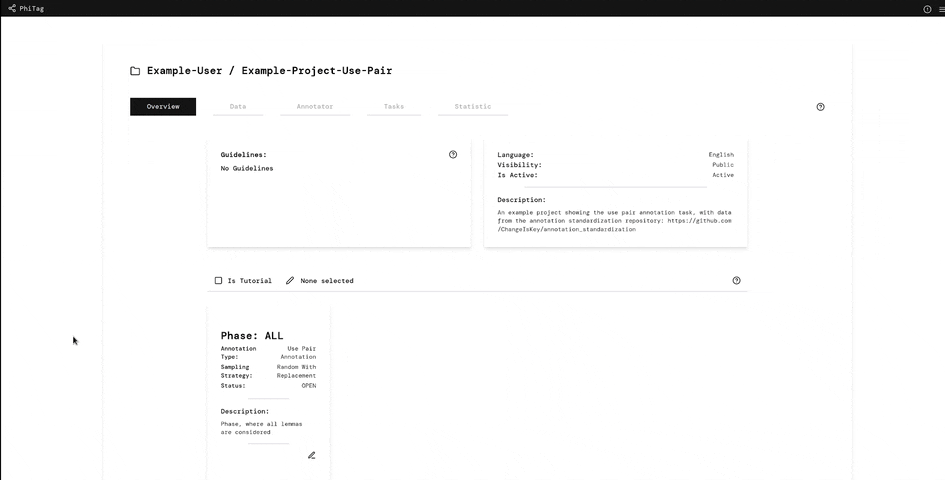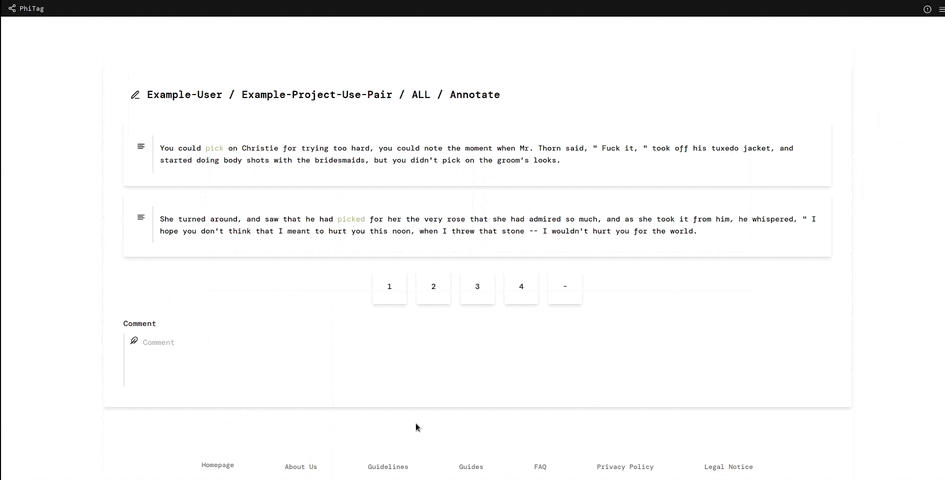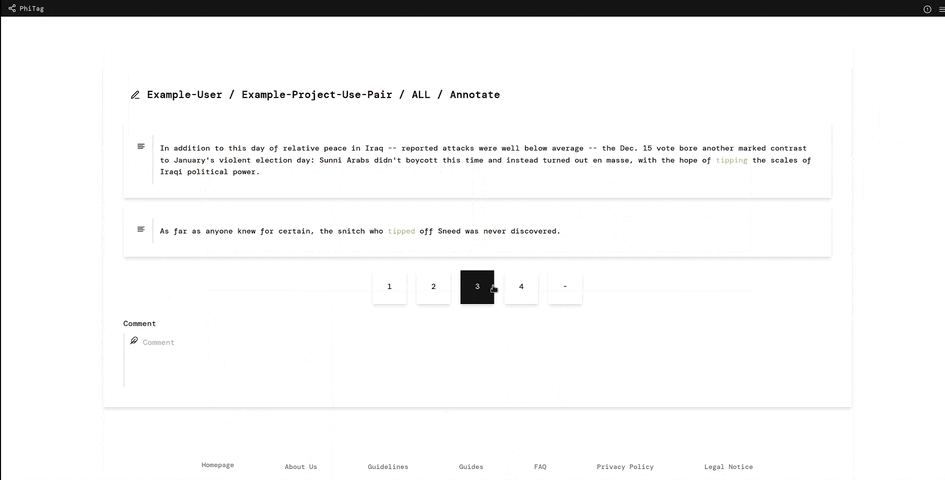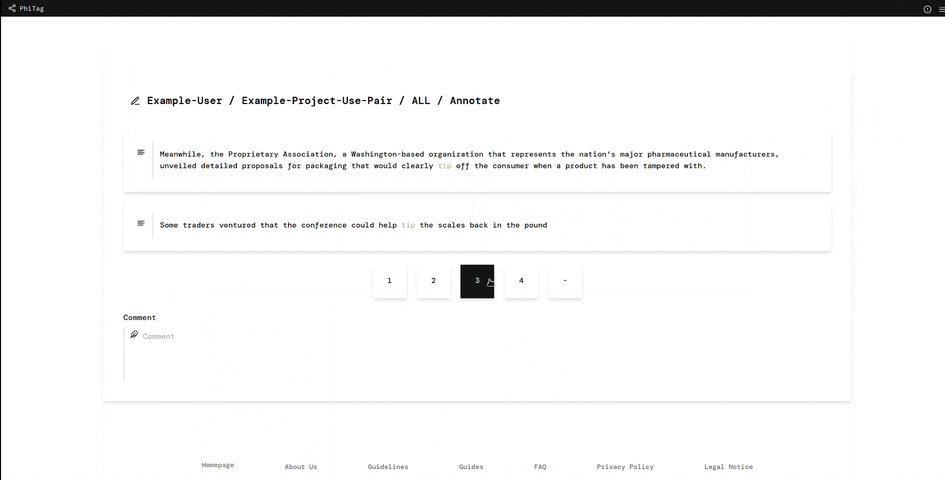
A simple use case for the PhiTag annotation platform is a recent research project at the Institute for Natural Language Processing at the University of Stuttgart. Researchers wanted to find words changing their meaning between two text corpora. Hence, they sampled a number of sentences per word from the two corpora and combined them into pairs like this one:
| Sentence 1 | Sentence 2 |
|---|---|
| He continued to grasp, between forefinger and thumb, the edge of the cloth I had been sewing. | For just a moment he didn't grasp the import of what the old man had said. |
The sentences and the combined pairs were then uploaded to the system and annotators had to choose a label from 1 (different meaning) to 4 (same meaning) deciding how related the pairs were. From the average relatedness value overall annotations, researchers could then estimate how much the word had changed. Simple, but effective!
Annotation Service
A typical use case for our annotation service is human text data labeling for model optimization. Automatic language processing models (sometimes called AIs) are used in many industry workflows or products. Such models profit from careful training and optimization on human-labeled ("gold") data. The most impressive example is OpenAI's ChatGPT whose success is attributed in large parts to optimization on human-labeled data (see this article for more information). Future successes of automatic language processing models are highly likely to involve training on human-labeled data. For this reason, PhiTag focuses on the standardization and optimization of human annotation processes to provide high-quality labeled data.
Lexicography
The lexicographical process of creating dictionaries is poorly automated. We believe that computational semantic text annotation models from NLP can substantially improve this process! That is why we added lexicographical functionalities to our text annotation platform PhiTag. The platform provides a simple and intuitive interface for viewing and editing your dictionaries and allows you to export your dictionaries to a variety of formats.
In the future, we plan to integrate dictionaries into the annotation process and provide more advanced functionality for your dictionaries and annotation projects. This includes automatic generation of dictionaries and suitable usages and tasks.
Check out our guide on how to use the dictionary functionality of the platform.